NLP in 2025: Building Production-Grade Language Systems
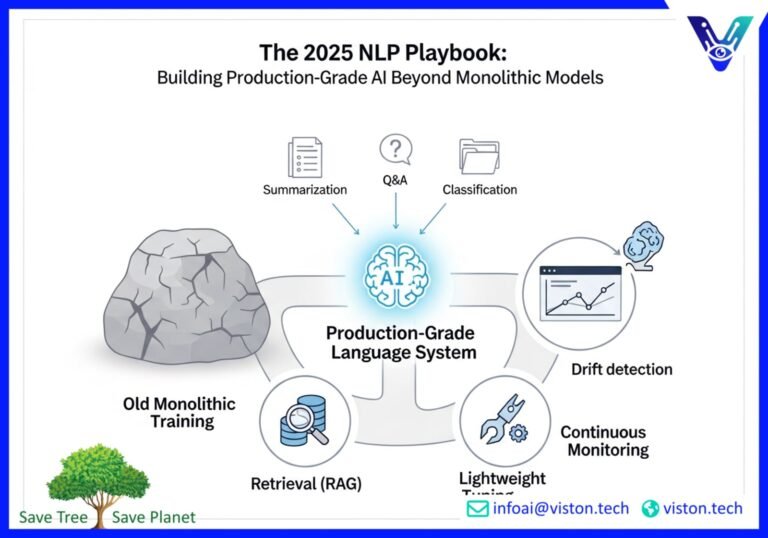
The world of Natural Language Processing (NLP) is moving at lightning speed. Gone are the days of monolithic models trained for months on end. Today, building production-grade language systems is a dynamic blend of sophisticated techniques. In 2025, success in production NLP hinges on a more agile and intelligent approach. This involves a contemporary mix of retrieval, lightweight tuning, and rigorous monitoring to deliver scalable and reliable AI-powered solutions.
For enterprises, AI/ML engineers, and product managers, understanding this shift is crucial. It’s the key to unlocking the full potential of NLP for complex tasks like summarization, Q&A, and classification at scale. This blog post will guide you through the modern workflow for creating robust language systems that deliver real-world value.
The New Paradigm: Beyond Monolithic Training
For years, the primary approach to NLP was to train massive, all-encompassing models from scratch. This was a resource-intensive process, demanding huge datasets and significant computational power. While this method produced powerful models, it was often slow, expensive, and inflexible.
The contemporary approach is far more nuanced. Instead of relying on a single, monolithic model, modern NLP systems are modular and adaptive. They combine the power of large language models (LLMs) with targeted, efficient techniques. This new paradigm emphasizes agility, cost-effectiveness, and the ability to adapt to ever-changing data.
Task Framing: Defining the “Why” Before the “How”
Before a single line of code is written, a critical first step is task framing. This is the process of clearly defining the problem you want to solve. It involves moving beyond a purely technical perspective and understanding the real-world needs the system will address.
For instance, instead of simply aiming to build a “summarization model,” a well-framed task would be to “create a tool that generates concise daily briefings for financial analysts from multiple news sources.” This clarity is essential for guiding every subsequent step of the development process.
Effective task framing involves answering key questions:
- What specific business problem are we solving?
- Who are the end-users, and what are their needs?
- How will the NLP system integrate into existing workflows?
- What does success look like, and how will we measure it?
By starting with a clear and user-centric frame, you set the foundation for a system that is not only technically sound but also genuinely useful.
Data Curation: The Unsung Hero of Production NLP
High-quality data is the lifeblood of any successful NLP system. Data curation is the meticulous process of collecting, cleaning, and organizing your data to ensure it is accurate, relevant, and representative of the real-world scenarios your model will encounter.
In 2025, data curation is more important than ever. With the rise of sophisticated models, the quality of the input data directly dictates the quality of the output. A well-curated dataset can significantly improve model performance and reduce the risk of bias.
Key aspects of data curation include:
- Data Sourcing: Identifying and gathering data from diverse and reliable sources.
- Data Cleaning: Removing noise, inconsistencies, and errors from the data.
- Data Annotation: Accurately labeling data to provide clear guidance for the model.
- Bias Detection and Mitigation: Proactively identifying and addressing potential biases in the dataset to ensure fairness.
Investing in robust data curation practices is a non-negotiable step for building production-grade language systems that are both effective and responsible.
Retrieval vs. Fine-Tuning: A Strategic Choice
One of the most significant shifts in modern NLP is the move away from extensive fine-tuning for every task. Instead, a powerful and often more efficient alternative has emerged: retrieval-augmented generation (RAG).
The Power of Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation is a technique that combines the generative power of LLMs with the ability to retrieve information from an external knowledge base. Instead of relying solely on the knowledge baked into the model during training, a RAG system can pull in real-time, relevant information to inform its responses.
This approach offers several key advantages:
- Up-to-Date Information: RAG systems can access the latest information, making them ideal for dynamic environments where knowledge is constantly evolving.
- Reduced Hallucinations: By grounding responses in external data, RAG can significantly reduce the risk of models generating inaccurate or fabricated information.
- Transparency: It’s often possible to trace the source of the information used to generate a response, providing a level of auditability that is crucial for many enterprise applications.
RAG has become a cornerstone of modern Q&A systems and is increasingly being used for other tasks like summarization and content generation.
When to Fine-Tune
While RAG offers many benefits, fine-tuning still has its place. Fine-tuning is the process of taking a pre-trained language model and further training it on a smaller, domain-specific dataset. This can be particularly effective for:
- Specialized Domains: For tasks that require deep knowledge of a specific niche, such as legal or medical text analysis, fine-tuning can help the model learn the unique vocabulary and nuances of that domain.
- Brand Voice and Style: Fine-tuning can be used to adapt a model to a specific brand voice or writing style, ensuring consistency in generated content.
The decision to use retrieval, fine-tuning, or a hybrid approach depends on the specific requirements of the task. In 2025, the most effective production NLP systems are often those that strategically combine these techniques. For more on this, explore the detailed comparisons available at resources like Red Hat’s analysis of RAG vs. fine-tuning.
Evaluation and Drift Monitoring: Ensuring Long-Term Success
Launching an NLP model into production is not the end of the journey. To ensure continued performance and reliability, a rigorous process of evaluation and drift monitoring is essential.
Comprehensive Evaluation
Evaluating an NLP model goes beyond simple accuracy metrics. A comprehensive evaluation framework should include a mix of quantitative metrics and qualitative analysis. This might involve:
- Standard Metrics: For tasks like classification at scale, metrics such as precision, recall, and F1-score are fundamental.
- Task-Specific Benchmarks: Using established benchmarks to compare model performance against industry standards.
- Human-in-the-Loop Evaluation: Involving human reviewers to assess the quality of model outputs for subjective tasks like summarization and Q&A.
A deep dive into evaluation techniques can be found at Milvus’s guide to evaluating NLP models.
Monitoring for Model Drift
Language is not static. It evolves over time, with new words, phrases, and contexts emerging constantly. This can lead to a phenomenon known as model drift, where a model’s performance degrades as the real-world data it encounters diverges from the data it was trained on.
Drift monitoring involves continuously tracking the performance of a production model and the statistical properties of the input data. By setting up automated alerts, you can be notified when significant drift is detected, allowing you to take corrective action, such as retraining the model with new data.
Proactive drift monitoring is crucial for maintaining the integrity and reliability of your NLP systems over the long term.
The Future is Agile and Integrated
The landscape of production NLP in 2025 is defined by a move towards more agile, modular, and integrated systems. The era of monolithic training is giving way to a more sophisticated approach that blends the power of large language models with the flexibility of retrieval, the precision of lightweight tuning, and the rigor of continuous monitoring.
By embracing this new paradigm, organizations can build production-grade language systems that are not only powerful but also scalable, adaptable, and reliable. This contemporary approach is essential for harnessing the full potential of NLP to solve real-world business problems and drive innovation.
Ready to build your own production-grade language system? Contact Viston AI today to learn how our AI-powered solutions can help you achieve your goals.
Frequently Asked Questions (FAQs)
1. What is production NLP?
Production NLP refers to the process of deploying Natural Language Processing models into a live environment where they can be used by end-users to perform real-world tasks. This involves not only building an accurate model but also ensuring it is scalable, reliable, and maintainable over time.
2. Why is data curation so important for production NLP systems?
Data curation is crucial because the quality of the data used to train an NLP model directly impacts its performance and fairness. A well-curated dataset helps to ensure that the model is accurate, robust, and free from biases, which is essential for any system operating in a production environment.
3. What is the main difference between retrieval-augmented generation (RAG) and fine-tuning?
The main difference lies in how the model accesses information. RAG connects a language model to an external knowledge base, allowing it to retrieve and use up-to-date information in real-time. Fine-tuning, on the other hand, adapts a pre-trained model to a specific domain by further training it on a specialized dataset. The knowledge becomes part of the model itself.
4. How does model drift affect NLP systems in production?
Model drift occurs when the statistical properties of the data the model sees in production change over time, diverging from the data it was trained on. This can lead to a significant degradation in the model’s performance and accuracy, making it less reliable for its intended task.
5. What are the key benefits of using a blended approach of retrieval, tuning, and monitoring?
A blended approach offers greater flexibility, efficiency, and reliability. Retrieval provides access to current information, lightweight tuning allows for domain-specific adaptation without the cost of full retraining, and continuous monitoring ensures the system remains accurate and effective over time. This combination allows for the creation of highly effective and maintainable production-grade NLP systems.
6. What are some common use cases for production-grade NLP?
Common use cases include advanced Q&A systems for customer support, automated text summarization of long documents, large-scale sentiment analysis of customer feedback, and sophisticated text classification for content moderation and organization.
7. How can I get started with building a production NLP system for my business?
A good starting point is to clearly define the problem you want to solve (task framing). From there, you can begin the process of data curation. For expert guidance and to leverage state-of-the-art tools and platforms, partnering with an AI solutions provider like Viston AI can significantly accelerate your path to a successful production deployment.
8. What are the challenges of scaling NLP models for production?
Scaling NLP models involves several challenges, including managing computational resources, ensuring low latency for real-time applications, maintaining data pipelines for continuous training and updates, and implementing robust monitoring to detect issues like model drift and performance degradation at scale.
#ProductionNLP #Summarization #QASystems #ClassificationAtScale #NLP2025 #AI #MachineLearning #LanguageSystems #VistonAI
