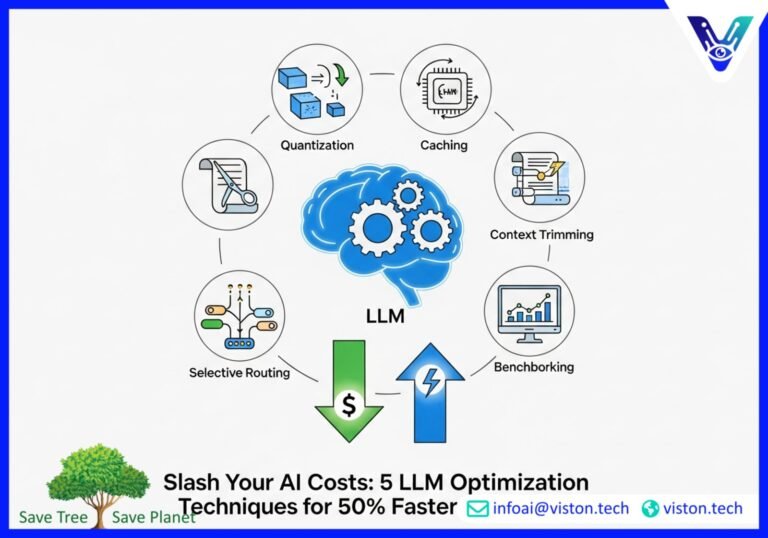
Slash Your AI Costs: 5 LLM Optimization Techniques for 50% Faster Responses
In today’s competitive landscape, Large Language Models (LLMs) are no longer a novelty; they are a core business engine. From powering customer service chatbots to accelerating content creation, their impact is undeniable. However, as organizations scale their AI initiatives, two critical challenges emerge: soaring operational costs and frustratingly slow response times. The very tools meant to boost efficiency can become a drain on resources. The good news? It doesn’t have to be this way.
Organizations at the forefront of AI adoption are reporting significant cost and latency improvements. How? By strategically combining a suite of powerful LLM optimization techniques. These aren’t just minor tweaks; they are fundamental shifts in how models are deployed and managed, leading to response times that are over 50% faster and a dramatic reduction in compute expenses. This article demystifies the core strategies that can transform your LLM deployments from a cost center into a powerful, efficient asset.
We will explore the essential levers you can pull to enhance inference speed and slash costs, focusing on practical, high-impact techniques like quantization and caching. Whether you’re a C-suite executive aiming to maximize ROI, an AI engineer tasked with performance, or a product manager designing the next generation of AI-powered features, this guide provides actionable insights for unlocking the true potential of your language models.
Understanding the Core Challenge: Latency and Cost
Before diving into the solutions, it’s crucial to understand the problem. When a user submits a query to an LLM, the model performs a complex series of calculations known as “inference” to generate a response. The time it takes to complete this process is the latency. For large, powerful models, this process is computationally intensive, requiring expensive hardware (like GPUs) and consuming significant energy. Every millisecond of delay and every processing cycle comes with a price tag.
For businesses, this translates into two major pain points:
- Poor User Experience: Slow, lagging AI responses can frustrate users and undermine the effectiveness of your application.
- Unsustainable Costs: The operational expenses of running LLMs at scale can quickly spiral, hindering widespread adoption and impacting your bottom line.
The solution lies in making the inference process smarter, not just faster. It’s about optimizing every step, from how the model is structured to how it processes information. Let’s explore the key techniques making this possible.
1. Quantization: The Power of “Good Enough” Precision
Imagine trying to measure a grain of sand with a ruler marked in kilometers. It’s overkill and inefficient. Similarly, LLMs are often trained using high-precision numbers (like 32-bit floating points) that require significant memory and processing power. Quantization is a powerful LLM optimization technique that reduces this precision. It converts the model’s parameters to use smaller data types, such as 8-bit or even 4-bit integers.
The Basic Idea: By using less precise numbers, the model becomes significantly smaller and computationally “lighter.” This has a direct and dramatic impact:
- Reduced Memory Footprint: A smaller model requires less RAM, allowing you to run powerful models on less expensive hardware.
–Faster Inference Speed: Calculations with smaller data types are much faster for computer processors to handle, directly cutting down latency.
While there can be a minor trade-off in accuracy, modern quantization methods are incredibly sophisticated. Techniques like Activation-aware Weight Quantization (AWQ) and SmoothQuant intelligently preserve the model’s performance, ensuring that the drop in precision is negligible for most enterprise use cases. The result is a much faster, more cost-effective model with nearly identical output quality.
2. Advanced Caching: Stop Re-doing the Same Work
One of the biggest inefficiencies in LLM inference is redundant computation. Every time an LLM generates a response, especially in a conversational context, it often re-processes parts of the input it has already seen. Caching is a simple yet profoundly effective technique that solves this problem by storing and reusing past computations.
The Basic Idea: The most impactful type of caching for LLMs is the KV Cache. In the Transformer architecture that underpins most LLMs, the “Key” (K) and “Value” (V) vectors are calculated for each token in the input. The KV Cache stores these vectors in high-speed GPU memory. When the next token is generated, the model can reuse the cached K and V vectors instead of re-calculating them for the entire preceding sequence. This transforms the computation from a resource-intensive quadratic problem into a much more manageable linear one, drastically accelerating text generation.
Think of it as the model having a short-term memory. Instead of re-reading the entire conversation from the beginning to understand the context for its next word, it simply refers to its cached “notes.” This leads to substantial gains in inference speed, making conversational AI applications feel much more responsive.
For more in-depth information on how memory and caching work, you can explore resources like this detailed guide on computer memory.
3. Context Trimming: Less is More
LLMs have a finite “context window”—the amount of text they can consider at one time. Longer contexts demand more memory and processing, increasing both latency and cost. Context trimming involves intelligently managing the information fed to the model to keep it within an optimal range.
The Basic Idea: Instead of feeding the entire conversational history or a full document into the model for every turn, context trimming strategies condense or shorten the input. Common methods include:
- Simple Truncation: Cutting off the oldest parts of the conversation.
- Summarization: Using a smaller, faster model to summarize earlier parts of the conversation and feeding that summary as context.
- Retrieval-Augmented Generation (RAG): Instead of providing a massive document, this technique retrieves only the most relevant snippets of text from a knowledge base at the time of the query.
By keeping the input context concise and relevant, you significantly reduce the computational load on the LLM. This not only speeds up responses but also directly lowers the cost per query, as most pricing models are based on the number of tokens processed.
4. Selective Routing: Using the Right Tool for the Job
Not all queries are created equal. A simple question doesn’t require the same horsepower as a request to write a complex legal document. Selective routing, also known as a mixture of experts or a model router, is a sophisticated strategy that directs incoming queries to the most appropriate LLM from a pool of available models.
The Basic Idea: An organization can maintain a portfolio of different LLMs. This might include a large, powerful (and expensive) model like GPT-4, alongside smaller, faster, and more specialized models. A lightweight “router” model first analyzes the user’s prompt to gauge its complexity or intent. Based on this analysis, it routes the query:
- Simple queries are sent to a small, fast, and cheap model.
- Complex or creative queries are sent to the large, state-of-the-art model.
- Domain-specific queries (e.g., medical or financial questions) could be routed to a fine-tuned expert model.
This approach ensures that you are not over-spending on compute resources for tasks that don’t require them. Organizations implementing selective routing have seen material cost reductions by ensuring that the bulk of their query volume is handled by highly efficient, lower-cost models, reserving the premium models for when they are truly needed.
5. Benchmarking and Cost-Per-Query Modeling
You can’t optimize what you can’t measure. The final, critical piece of the LLM optimization puzzle is a robust system for benchmarking and analyzing the cost-per-query. This is the foundation upon which all other optimization strategies are built.
The Basic Idea: Benchmarking involves systematically testing your models and infrastructure to measure key performance indicators (KPIs) like latency (time to first token and total generation time) and throughput (queries per second). This data allows you to:
- Establish a Baseline: Understand your current performance and costs.
- Evaluate Optimizations: Quantify the impact of techniques like quantization and caching. For instance, you can directly compare the latency and cost of a quantized model versus its full-precision counterpart.
- Build a Cost-Per-Query Model: By combining performance data with infrastructure costs, you can calculate the exact cost of answering a single query. This enables you to make informed decisions about model selection, hardware provisioning, and pricing for your AI services.
A clear understanding of your cost and performance metrics empowers you to build a business case for optimization efforts and demonstrate a clear return on investment. Tools and leaderboards, like the one provided by Artificial Analysis, can offer valuable comparative data.
Bringing It All Together: The Compounding Effect
The true power of these LLM optimization techniques is realized when they are used in combination. Imagine a system where:
- A selective router first sends a query to a smaller, quantized model.
- That model leverages a KV Cache to rapidly process the conversational context, which has already been shortened via context trimming.
- All of this is tracked through a continuous benchmarking process that validates cost savings.
This synergistic approach creates a compounding effect, where each optimization enhances the others. The result is a highly efficient, scalable, and cost-effective LLM deployment that delivers a superior user experience and a stronger bottom line. The reports of 50% faster responses and material cost gains are not aspirational; they are the tangible outcomes of a well-executed LLM optimization strategy.
Take Action with Viston AI
Navigating the complexities of LLM optimization requires expertise and the right tools. If you are ready to unlock these material gains in speed and cost for your organization, the team at Viston AI is here to help. We specialize in creating and deploying highly optimized, enterprise-grade AI solutions.
Contact Viston AI today to learn how our AI-powered solutions can accelerate your journey to efficient, scalable, and cost-effective Large Language Model deployments. Let’s build the future of AI, together.
Frequently Asked Questions (FAQs)
1. What is LLM optimization?
LLM optimization is the process of improving the performance, speed, and cost-efficiency of Large Language Models. It involves a range of techniques, including quantization, caching, and selective routing, to reduce latency and computational costs without significantly compromising the model’s accuracy.
2. How does quantization make LLMs faster?
Quantization reduces the numerical precision of a model’s parameters (e.g., from 32-bit to 8-bit numbers). This makes the model smaller and the calculations required for inference much faster for processors to handle, leading to lower latency and reduced memory usage.
3. What is the main benefit of caching in LLMs?
The primary benefit of caching, particularly KV Caching, is the reduction of redundant computations. By storing and reusing intermediate calculations from previous tokens in a sequence, it dramatically speeds up the generation of new text, which is especially impactful for conversational AI and long-form content generation.
4. Can LLM optimization techniques reduce my operational costs?
Absolutely. Techniques like selective routing (using cheaper models for simple tasks), context trimming (reducing the amount of data processed), and quantization (enabling the use of less expensive hardware) all contribute to significant reductions in the operational costs associated with running LLMs at scale.
5. Is there a trade-off between optimization and accuracy?
While some aggressive optimization techniques can slightly impact model accuracy, modern methods are designed to minimize this trade-off. For most enterprise applications, the small potential decrease in precision from techniques like quantization is imperceptible to the end-user and is far outweighed by the substantial gains in speed and cost-efficiency.
6. What is the difference between latency and throughput in LLMs?
Latency is the time it takes for the model to generate a response to a single query (often measured as “time to first token” or total generation time). Throughput is the number of queries the system can handle in a given period (e.g., requests per second). Both are critical metrics for evaluating the performance of an LLM deployment.
7. How do I start with LLM optimization for my business?
A good starting point is to benchmark your current LLM deployment to understand your baseline performance and costs. From there, you can begin implementing high-impact, low-complexity techniques like KV Caching. For more comprehensive strategies involving quantization and model routing, partnering with experts like Viston AI can help accelerate your progress and ensure you are using the most effective techniques for your specific use case.
8. What is selective routing for LLMs?
Selective routing is an advanced strategy where a system uses multiple LLMs and a “router” model. The router analyzes incoming user prompts and directs them to the most suitable model—a small, fast one for simple tasks or a large, powerful one for complex tasks—thereby optimizing for both cost and performance.
