MLOps at Scale: From Model Training to Production Monitoring
The journey of a machine learning model from a data scientist’s notebook to a production environment is fraught with challenges. A staggering statistic haunts the AI industry: a significant percentage of machine learning models never make it into production. Of those that do, many fail to deliver their expected value due to a silent but critical issue: poor observability. This is where MLOps, or Machine Learning Operations, transforms from a buzzword into a business imperative. In this post, we’ll explore how a modern approach to MLOps, often called MLOps 2.0, can drastically reduce the risk of deployment failure and enable you to scale your AI initiatives with confidence.
The Ailing 75%: Why Most AI Initiatives Stumble
Imagine investing millions in developing a state-of-the-art machine learning model, only for it to underperform or, worse, fail silently in production. This is the unfortunate reality for many organizations. The primary culprit is a lack of robust monitoring and observability. Without the ability to track a model’s performance in real-time, it’s impossible to detect the subtle degradation that can render it ineffective or even harmful to your business. This is where the principles of MLOps 2.0 come into play, offering a lifeline to struggling AI projects.
Enter MLOps 2.0: The Next Generation of AI Operations
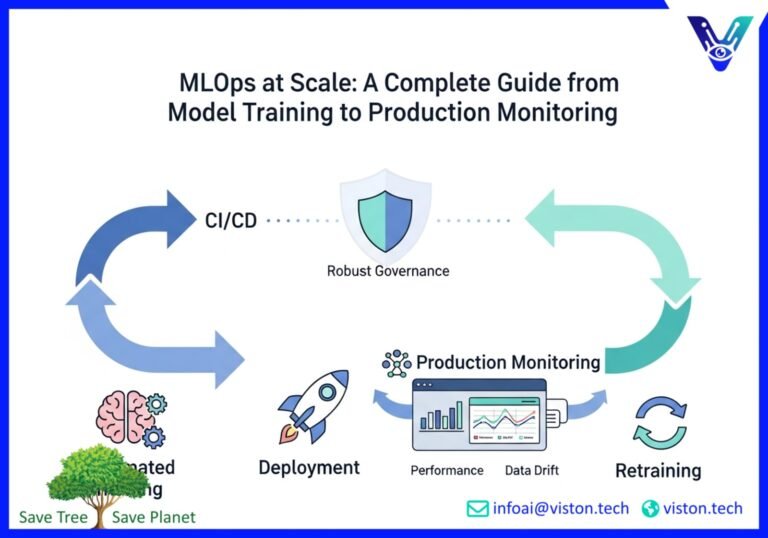
MLOps is the application of DevOps principles to the machine learning lifecycle. It’s about creating a streamlined and automated process for building, testing, deploying, and monitoring machine learning models. MLOps 2.0 takes this a step further by emphasizing three core pillars that are essential for scaling AI successfully:
- Automated Training: Gone are the days of manual model retraining. Modern MLOps platforms enable continuous training (CT), where models are automatically retrained on new data to ensure they remain accurate and relevant. This is a crucial defense against model drift, where a model’s performance degrades over time as the real-world data it encounters diverges from the data it was trained on.
- Continuous Monitoring: This is the heart of observability. Continuous monitoring involves tracking a wide range of metrics in real-time to get a holistic view of your model’s health. This goes beyond simple accuracy to include data quality, drift detection, and fairness. With continuous monitoring, you can catch issues before they impact your bottom line.
- Robust Governance: As AI becomes more integrated into business-critical processes, model governance is no longer optional. MLOps 2.0 provides the framework for ensuring that your models are not only performing well but are also compliant with internal policies and external regulations. This includes maintaining a clear audit trail, managing model versions, and ensuring fairness and transparency.
The Modern MLOps Tools Landscape: Your Arsenal for Success
The MLOps tools market is rapidly evolving, with a rich ecosystem of platforms designed to help you implement a robust MLOps strategy. These tools can be broadly categorized into end-to-end platforms and specialized solutions that address specific parts of the machine learning lifecycle. Here’s a look at some of the key players and categories you should be aware of in 2025:
End-to-End MLOps Platforms
These platforms provide a comprehensive solution for managing the entire machine learning lifecycle, from data preparation to production monitoring. They are an excellent choice for organizations looking for a unified and streamlined approach to MLOps.
- Vertex AI (Google Cloud): A unified platform that offers a wide range of tools for building, deploying, and managing ML models at scale.
- Amazon SageMaker: A fully managed service from AWS that provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly.
- Azure Machine Learning: Microsoft’s cloud-based environment you can use to train, deploy, automate, manage, and track ML models.
Specialized MLOps Tools
For organizations that prefer a more modular approach, there are numerous specialized tools that excel at specific MLOps tasks:
- Experiment Tracking: Tools like MLflow and Neptune.ai help you log and compare your machine learning experiments, ensuring reproducibility and collaboration.
- Model Serving: Platforms such as KServe and Seldon Core are designed for deploying and serving machine learning models at scale, often on Kubernetes.
- Monitoring and Observability: Solutions from companies like Arize AI and Fiddler AI provide deep insights into your model’s performance in production, with a focus on drift detection and explainability.
For a deeper dive into the tools available, check out this comprehensive MLOps Landscape in 2025.
Your Essential Machine Learning Model Monitoring Checklist
Effective monitoring is the cornerstone of successful MLOps at scale. It’s not just about knowing if your model is “up” or “down”; it’s about understanding its behavior in the real world. A well-defined monitoring strategy is your first line of defense against the silent failures that plague so many AI initiatives. Here is a checklist of key areas to monitor to ensure your models remain healthy and effective in production:
1. Model Performance Metrics
- Business-Relevant KPIs: Track metrics that directly align with your business objectives. This could be click-through rates, conversion rates, or fraud detection accuracy.
- Statistical Metrics: Monitor standard machine learning metrics like precision, recall, F1-score for classification models, and RMSE or MAE for regression models.
2. Data and Concept Drift Detection
- Input Data Drift: Monitor the statistical properties of your input data to detect any significant changes from the training data. This is a leading indicator of potential performance degradation.
- Prediction Drift: Track the distribution of your model’s predictions. A sudden shift can indicate a change in the underlying data or a problem with the model itself.
- Concept Drift: This is a more subtle form of drift where the relationship between your input features and the target variable changes over time. This often requires more advanced monitoring techniques to detect.
3. Data Quality and Integrity
- Data Schema Changes: Ensure that the structure of the incoming data matches the schema your model was trained on. Unexpected changes can break your model.
- Data Integrity Issues: Monitor for missing values, outliers, and other data quality problems that can impact your model’s performance.
4. Operational Health
- Latency: Track the time it takes for your model to make a prediction. High latency can lead to a poor user experience.
- Throughput: Monitor the number of predictions your model is making over a given period. This can help you identify performance bottlenecks.
- Error Rates: Keep an eye on the rate of errors in your model’s predictions. A sudden spike can indicate a serious problem.
5. Fairness and Bias
- Demographic Parity: If your model is making decisions that affect people, it’s crucial to monitor for bias across different demographic groups.
- Equal Opportunity: Ensure that your model is performing equally well for all subgroups of your user population.
For a more detailed checklist, consider this Machine Learning Model Monitoring Checklist.
CI/CD for AI: Automating the Path to Production
Continuous Integration and Continuous Delivery (CI/CD) are foundational practices in modern software development. When applied to machine learning, they form the backbone of a robust MLOps strategy. CI/CD for AI automates the process of building, testing, and deploying machine learning models, enabling you to release new models and updates quickly and reliably.
A typical CI/CD pipeline for AI includes the following stages:
- Code and Data Versioning: All code and data used to train the model are version-controlled, ensuring reproducibility.
- Automated Testing: The pipeline includes automated tests for both the code and the model, including unit tests, integration tests, and model validation tests.
- Automated Model Training: The model is automatically trained and retrained as new code or data is committed.
- Automated Deployment: Once the model passes all tests, it is automatically deployed to a staging or production environment.
The Power of Modern MLOps Platforms
Adopting a modern MLOps platform is no longer a luxury; it’s a necessity for any organization that wants to succeed with AI. These platforms provide the automation, observability, and governance capabilities you need to overcome the challenges of deploying and managing machine learning models at scale. By investing in a robust MLOps strategy, you can:
- Reduce Deployment Risk: Automated testing and continuous monitoring help you catch issues early, reducing the risk of deploying a faulty model.
- Increase Speed and Agility: CI/CD for AI enables you to release new models and updates faster, allowing you to respond more quickly to changing business needs.
- Improve Model Performance: Continuous training and drift detection ensure that your models remain accurate and relevant over time.
- Enable Scale: A solid MLOps foundation provides the stability and efficiency you need to scale your AI initiatives across the enterprise.
Conclusion: From Fragile Models to Resilient AI Systems
The high failure rate of AI initiatives is not a reflection of the potential of machine learning, but rather a symptom of a broken process. By embracing the principles of MLOps 2.0—automated training, continuous monitoring, and robust governance—you can transform your AI projects from high-risk gambles into reliable and scalable business assets. The future of AI belongs to those who can not only build intelligent models but also operate them with discipline and precision. Modern MLOps platforms provide the tools to do just that, turning the promise of AI into tangible business value.
Ready to de-risk your AI deployments and scale with confidence? Contact Viston AI today to learn how our AI-powered solutions can help you build a world-class MLOps practice.
#MLOps #ModelGovernance #Observability #DriftDetection #CIforAI #CDforAI #AIPoweredSolutions
Frequently Asked Questions (FAQs)
What is MLOps?
MLOps, or Machine Learning Operations, is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. It’s the application of DevOps principles to the machine learning lifecycle, focusing on automation, collaboration, and continuous improvement.
Why is model governance important in MLOps?
Model governance is crucial for ensuring that your machine learning models are not only accurate but also fair, transparent, and compliant with regulations. It involves managing the entire lifecycle of your models, from development to retirement, and providing a clear audit trail for all decisions made.
What is drift detection in machine learning?
Drift detection is the process of identifying changes in the statistical properties of your data over time. There are two main types of drift: data drift, which is a change in the input data, and concept drift, which is a change in the relationship between the input data and the target variable. Drift detection is essential for maintaining the accuracy of your models in production.
How does CI/CD for AI work?
CI/CD for AI automates the process of building, testing, and deploying machine learning models. It typically involves a pipeline that is triggered by changes to the code or data. The pipeline automatically trains, tests, and validates the model before deploying it to production, ensuring a fast and reliable release process.
What are the key components of a good MLOps platform?
A comprehensive MLOps platform should include tools for experiment tracking, model versioning, automated training and deployment, and production monitoring. It should also provide robust governance features, such as access control, audit trails, and fairness and bias detection.
How can MLOps help reduce the failure rate of AI projects?
MLOps helps reduce the failure rate of AI projects by providing the tools and processes needed to manage the entire machine learning lifecycle effectively. By automating key tasks, improving collaboration, and providing deep insights into model performance, MLOps helps organizations deploy and maintain high-quality models that deliver real business value.
What is the difference between model monitoring and observability?
Model monitoring is the process of tracking key metrics to ensure that your models are performing as expected. Observability, on the other hand, is a more holistic approach that involves collecting and analyzing a wide range of data to understand the internal state of your models and diagnose any issues that may arise.
How do I get started with MLOps?
A good starting point is to assess your current machine learning processes and identify areas where you can introduce automation and standardization. You can then start to explore different MLOps tools and platforms to find the ones that best fit your needs. It’s also important to foster a culture of collaboration between your data science, engineering, and operations teams.
