Context Engineering for Agents: Master the Attention Budget
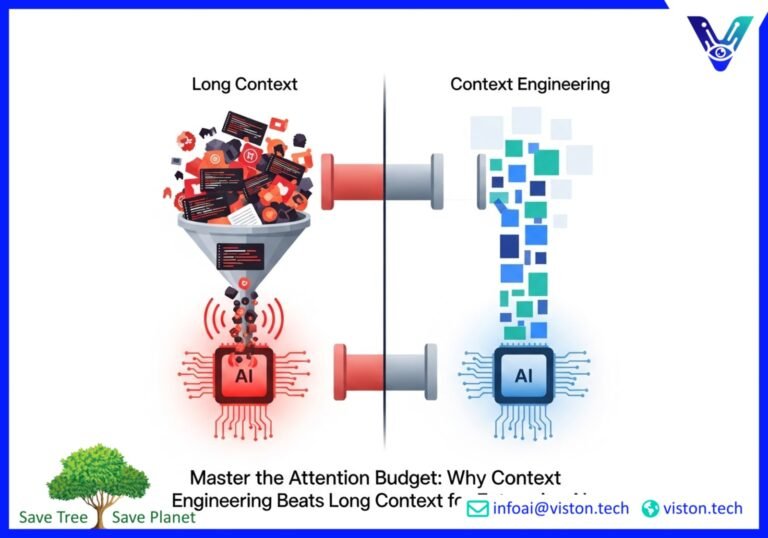
The race for larger context windows in AI is a distraction. While brute-forcing massive amounts of data into a large language model (LLM) seems appealing, it’s an inefficient and often ineffective strategy in production environments. The key to unlocking reliable, high-performing AI agents in 2025 isn’t about having the biggest “memory” but the smartest. Welcome to the era of Context Engineering, a disciplined approach that prioritizes retrieval quality and intelligent prompt strategies over sheer volume.
For enterprise leaders, AI engineers, and product managers, understanding this shift is critical. It’s the difference between a flashy demo and a scalable, cost-effective AI solution that delivers real business value. This post dives into why a disciplined context policy, powered by advanced retrieval techniques, consistently outperforms the brute-force method.

The Illusion of Infinite Memory: Why Long-Context Windows Fail in Production
The idea of a massive context window—the LLM’s working memory—is seductive. It promises a world where you can feed an entire database to an AI and get perfect answers. However, this approach has significant practical limitations:
- Skyrocketing Costs and Latency: Processing millions of tokens for every query is expensive and slow. In a business context where speed and budget matter, this is a non-starter. Studies show that smart retrieval methods can be up to 82 times cheaper than long-context approaches.
- Context Rot and the “Needle in a Haystack” Problem: As the context window fills, an LLM’s performance can degrade. It struggles to distinguish critical information from noise, leading to a phenomenon known as “context rot.” Important details get lost, and the model’s attention drifts.
- Increased Risk of Hallucinations: More data doesn’t always mean better answers. When an LLM is overwhelmed with information, it’s more likely to generate plausible but incorrect “facts,” undermining the reliability of your application.
Simply put, a bigger bucket for information doesn’t help if you’re filling it with irrelevant junk. The goal isn’t to make the AI remember everything; it’s to help it pay attention to the right things at the right time. This is the core principle of context engineering.
What is Context Engineering? A Disciplined Approach
Context engineering is the evolution of prompt engineering. While prompt engineering focuses on crafting the perfect instruction for a single task, context engineering designs the entire information ecosystem for an AI agent. It’s a strategic approach to managing an AI’s limited attention budget by ensuring that every piece of information in the context window is relevant, precise, and serves a purpose.
A robust context engineering strategy is built on four pillars: writing, selecting, compressing, and isolating context. This structured approach ensures that the AI has exactly what it needs for the task at hand without being overloaded.
At its heart, context engineering is about a disciplined context policy. This isn’t a single technique but a comprehensive strategy that governs how information is retrieved, filtered, and presented to the LLM. It’s about being deliberate with every token you use.
The Foundation: A Smart Context Policy
A well-defined context policy acts as the brain of your AI agent. It decides what information is necessary for a given task and what is simply noise. This policy is not static; it dynamically adapts to the user’s query and the conversation’s history. Key elements of an effective context policy include:
- Dynamic Information Retrieval: Instead of loading static documents, the system fetches information on the fly based on the immediate query.
- Hierarchical Memory Systems: It distinguishes between short-term memory (the current conversation), and long-term memory (persistent user data or foundational knowledge), and retrieves from each as needed.
- Purpose-Driven Context: Every piece of information added to the context window has a clear role, whether it’s providing instructions, grounding the model in facts, or defining the tools it can use.
Retriever Tuning: The Engine of High-Quality Context
The quality of your AI’s output is directly tied to the quality of the information it retrieves. This is where retrieval quality becomes paramount. Simple keyword or vector search is no longer enough. Modern, production-grade AI agents rely on hybrid retrieval systems that offer the best of both worlds.
Hybrid Retrieval: The Best of Both Worlds
Hybrid retrieval combines different search methods to achieve superior accuracy and relevance. The most common and effective pairing is:
- Dense Retrieval (Vector Search): This method excels at understanding the semantic or conceptual meaning behind a query. It’s great for finding information that is thematically related, even if the keywords don’t match exactly.
- Sparse Retrieval (Keyword Search, e.g., BM25): This traditional method is highly effective at matching specific terms, jargon, product codes, or names. It ensures that critical, exact-match keywords are not missed.
By fusing the results of both methods, a hybrid system captures both conceptual relevance and keyword precision. This dramatically reduces the chances of the retriever missing crucial documents, a common failure point for systems that rely on a single search method.
Beyond Retrieval: The Importance of Reranking
Once an initial set of documents is retrieved, the process isn’t over. A reranking step is crucial for refining the results. A secondary, more sophisticated model (often a cross-encoder) evaluates the initial retrieved chunks against the specific query to score their relevance more accurately. This ensures that the most pertinent information is placed at the top of the context, where the LLM is most likely to pay attention.
Metadata and Chunking: The Unsung Heroes of Retrieval
How you structure your data before it ever gets to the retrieval stage is just as important as the retrieval algorithm itself. This is where strategic metadata and chunking come into play.
Strategic Chunking for Better Context
Chunking is the process of breaking down large documents into smaller, digestible pieces. A naive approach, like splitting a document every 1,000 characters, can sever related ideas and destroy context. Effective chunking strategies are more nuanced:
- Semantic Chunking: This method breaks down text based on semantic meaning, ensuring that complete thoughts or concepts are kept together in a single chunk.
- Sentence-Based Chunking: By keeping full sentences intact, this approach preserves logical flow and readability.
- Metadata-Augmented Chunking: Attaching metadata to each chunk provides additional context that the retrieval system can use.
The Power of Rich Metadata
Metadata—data about your data—is a powerful tool for improving retrieval quality. By tagging your data chunks with relevant information, you enable a more precise and filtered search. Important metadata can include:
- Source Information: Document titles, authors, and publication dates.
- Hierarchical Context: Section headings or chapter titles to show where the chunk fits into the larger document.
- Timestamps and Recency: Crucial for time-sensitive information.
- Access Permissions: Ensuring the AI only retrieves information the user is authorized to see.
With rich metadata, your retrieval system can perform filtered searches, such as finding information only within documents published in the last year or from a specific department. This level of precision is impossible with brute-force long-context methods.
Evaluation with Factual Probes: How to Know if It’s Working
You can’t improve what you can’t measure. In the world of AI agents, ensuring factual accuracy, or grounding, is critical. One of the most effective ways to evaluate the performance of your context engineering strategy is through the use of factual probes.
A factual probe is a question with a known, verifiable answer that can be found within your knowledge base. By systematically testing your AI agent with a suite of these probes, you can measure key performance indicators:
- Retrieval Recall: Did the system successfully retrieve the document containing the correct answer?
- Retrieval Precision: Of the documents retrieved, how many were actually relevant to the question?
- Generation Accuracy: Did the LLM use the retrieved context to generate the correct answer?
- Absence of Hallucination: Did the model avoid making up information not present in the source documents?
Frameworks like Google’s FACTS Grounding provide a structured way to benchmark the factuality of LLM responses against provided source material. Regularly evaluating your system with factual probes allows you to identify weaknesses in your context policy, retriever tuning, or chunking strategy and make data-driven improvements. This iterative process of testing and refining is what separates production-ready AI from fragile prototypes.
The Future is Disciplined, Not Brute-Force
The allure of ever-expanding context windows is a red herring. While larger models will continue to emerge, the fundamental principles of attention and relevance will remain. The most successful and reliable enterprise AI solutions in 2025 and beyond will not be those that simply dump data into a massive context window. They will be the ones built on a foundation of disciplined context engineering.
By implementing a thoughtful context policy, fine-tuning your retrieval systems with hybrid search and reranking, strategically structuring your data with smart chunking and metadata, and rigorously testing with factual probes, you can build AI agents that are not only powerful but also efficient, reliable, and trustworthy.
It’s time to move beyond the brute-force approach and master the attention budget. The future of enterprise AI depends on it.
Ready to build enterprise-grade AI solutions that deliver real results? Contact Viston AI today to learn how our expertise in context engineering and advanced AI systems can help you unlock the true potential of your data.
Frequently Asked Questions (FAQs)
What is the difference between context engineering and prompt engineering?
Prompt engineering focuses on crafting the best possible single instruction (prompt) to get a desired output from an LLM. Context engineering is a broader discipline that involves designing the entire system for managing the information (context) an AI agent receives over time. It includes prompt strategy, but also memory management, data retrieval, and tool integration to ensure consistent performance on complex tasks.
Why is a large context window not always better?
While a large context window can hold more information, it often leads to higher costs, increased latency, and a drop in performance known as “context rot.” The model can get distracted by irrelevant information, lose track of key details, and is more prone to hallucination. A smaller, well-curated context is often more effective and efficient.
What is hybrid retrieval and why is it important for retrieval quality?
Hybrid retrieval combines multiple search techniques, typically dense (semantic) and sparse (keyword) search. This approach improves retrieval quality by capturing both the conceptual meaning of a query and exact-match terms. It ensures more relevant and comprehensive results are returned to the LLM, leading to more accurate answers.
How does strategic chunking improve AI performance?
Strategic chunking breaks large documents into smaller, coherent pieces while preserving their meaning. Unlike simple fixed-size chunking, methods like semantic chunking keep related ideas together. This provides the AI with more meaningful and complete context, which improves the relevance and accuracy of its generated responses.
What are factual probes and how are they used for evaluation?
Factual probes are questions with known, objective answers that exist within a given knowledge base. They are used to evaluate an AI system’s performance by testing its ability to retrieve the correct information and generate a factually accurate answer. This process helps measure the system’s grounding and identify areas for improvement in the context engineering pipeline.
Can a good context policy reduce AI operational costs?
Absolutely. By focusing on providing only the most relevant information, a disciplined context policy drastically reduces the number of tokens that need to be processed for each query. This directly translates into lower API costs and reduced computational load, making the AI system more scalable and cost-effective in a production environment.
What is “grounding” in the context of AI agents?
Grounding refers to the ability of an AI agent to base its responses firmly on the provided source information and avoid making up facts (hallucinating). A well-grounded AI can cite its sources and provide answers that are verifiable and trustworthy, which is crucial for enterprise applications.
How does metadata impact retrieval quality?
Metadata adds an extra layer of context to your data chunks, allowing for more sophisticated and precise retrieval. By using metadata tags like dates, authors, or document sections, you can filter search results to quickly narrow down to the most relevant information, significantly boosting the overall quality and speed of the retrieval process.
