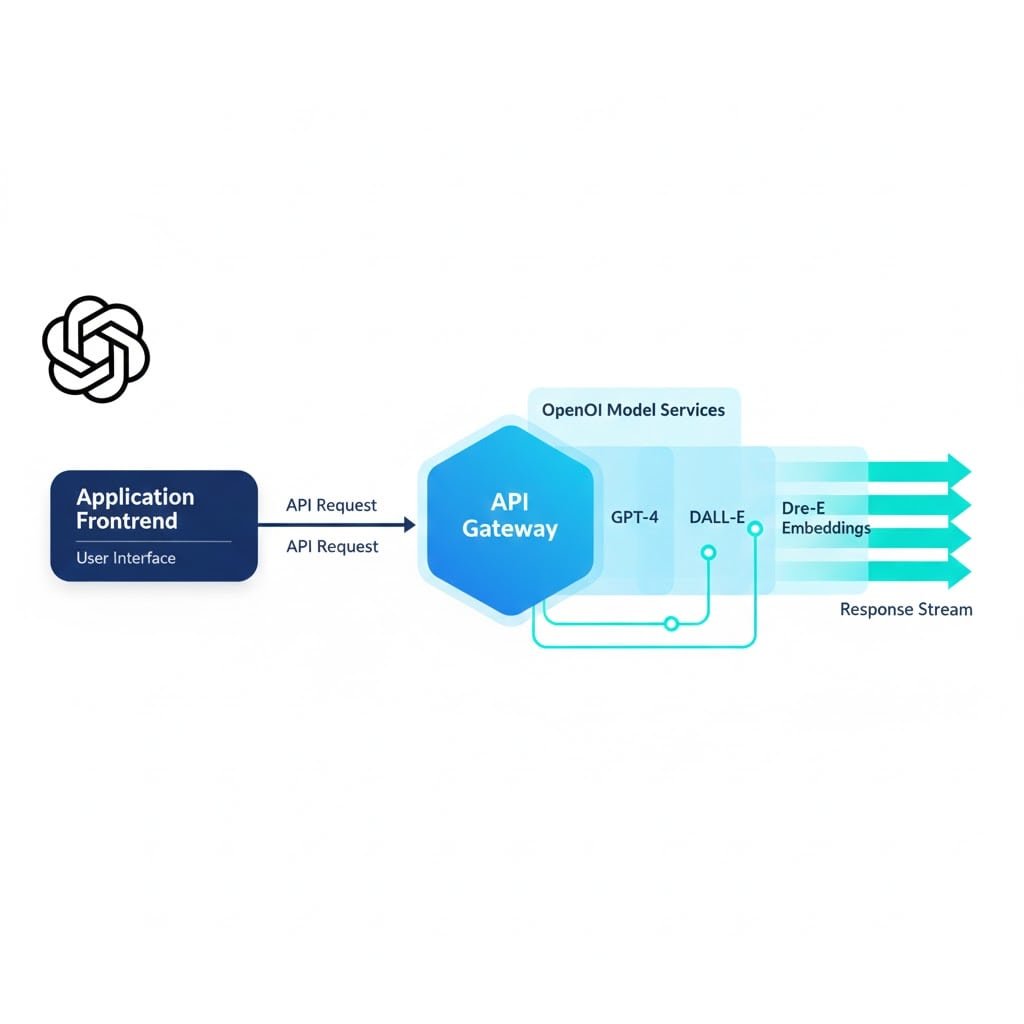
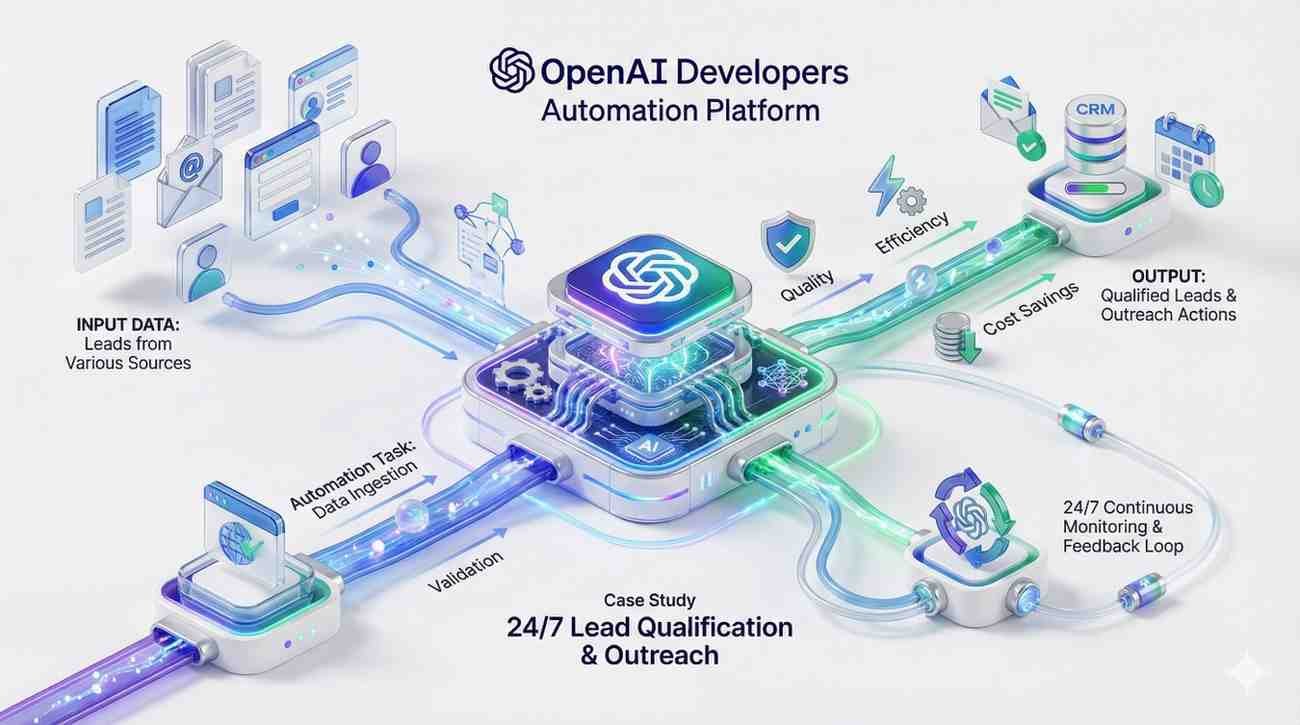
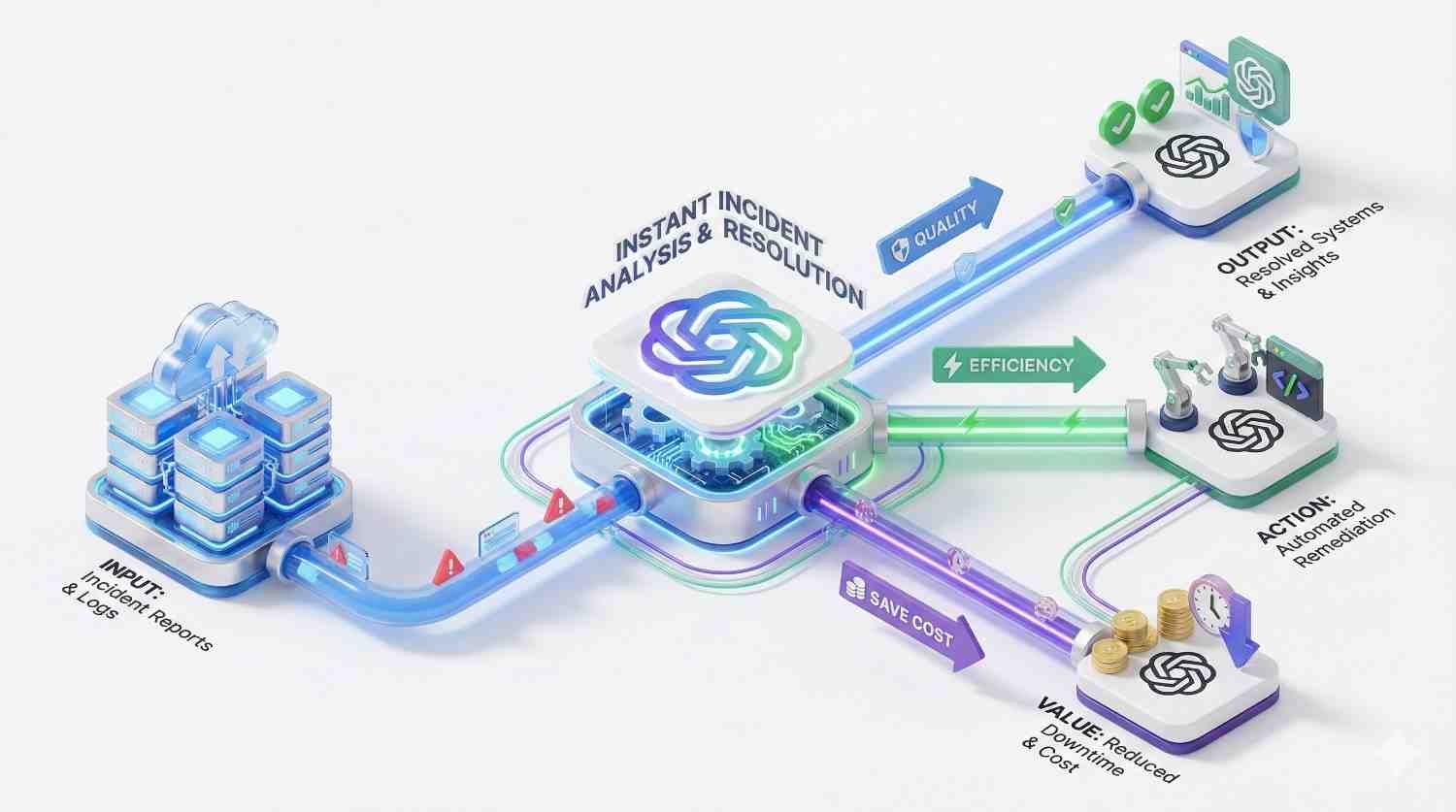
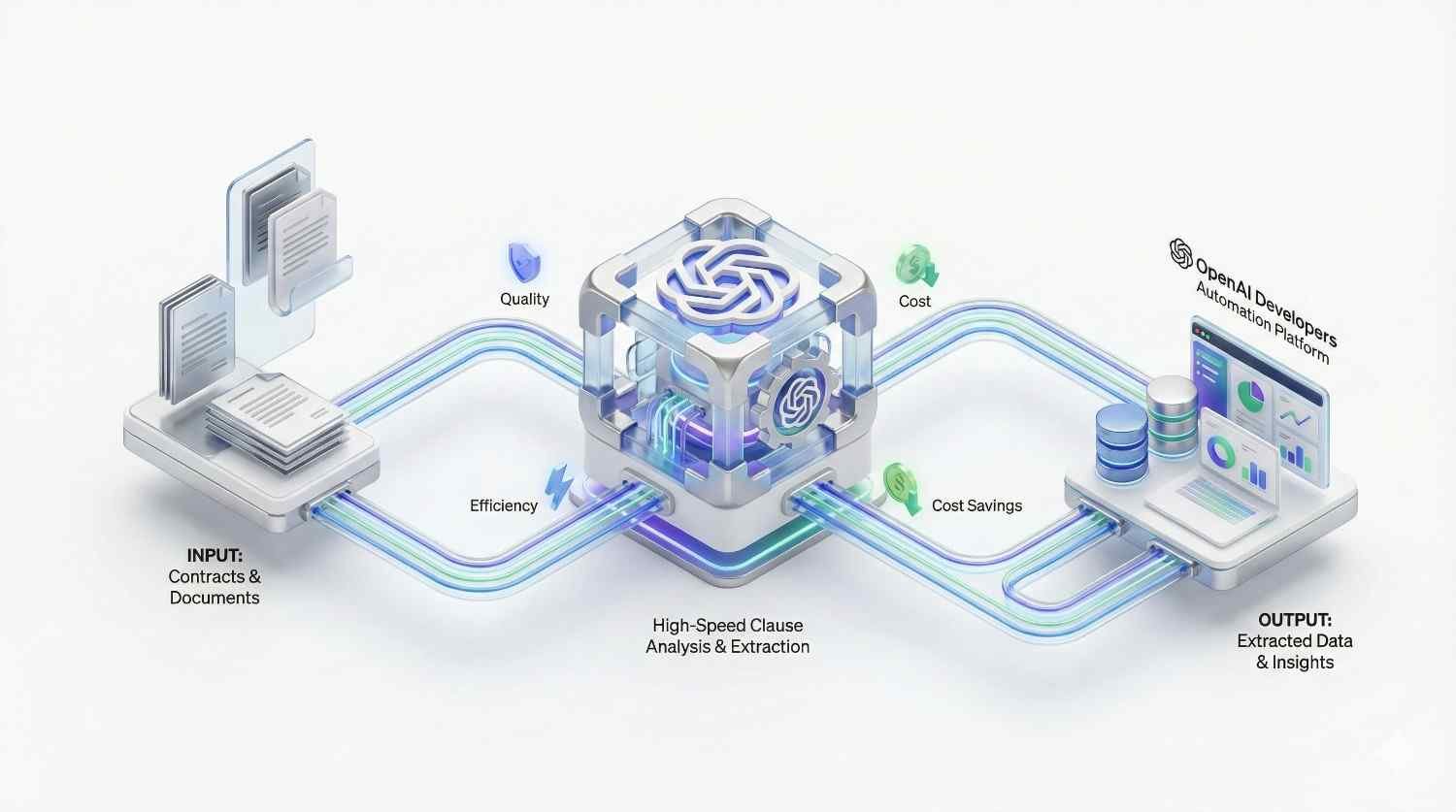
Yes. While RAG is often sufficient, we offer full fine-tuning services. We prepare your training datasets, manage the fine-tuning jobs, and evaluate the custom model against benchmarks to ensure it understands your specific medical, legal, or technical terminology better than the base model.