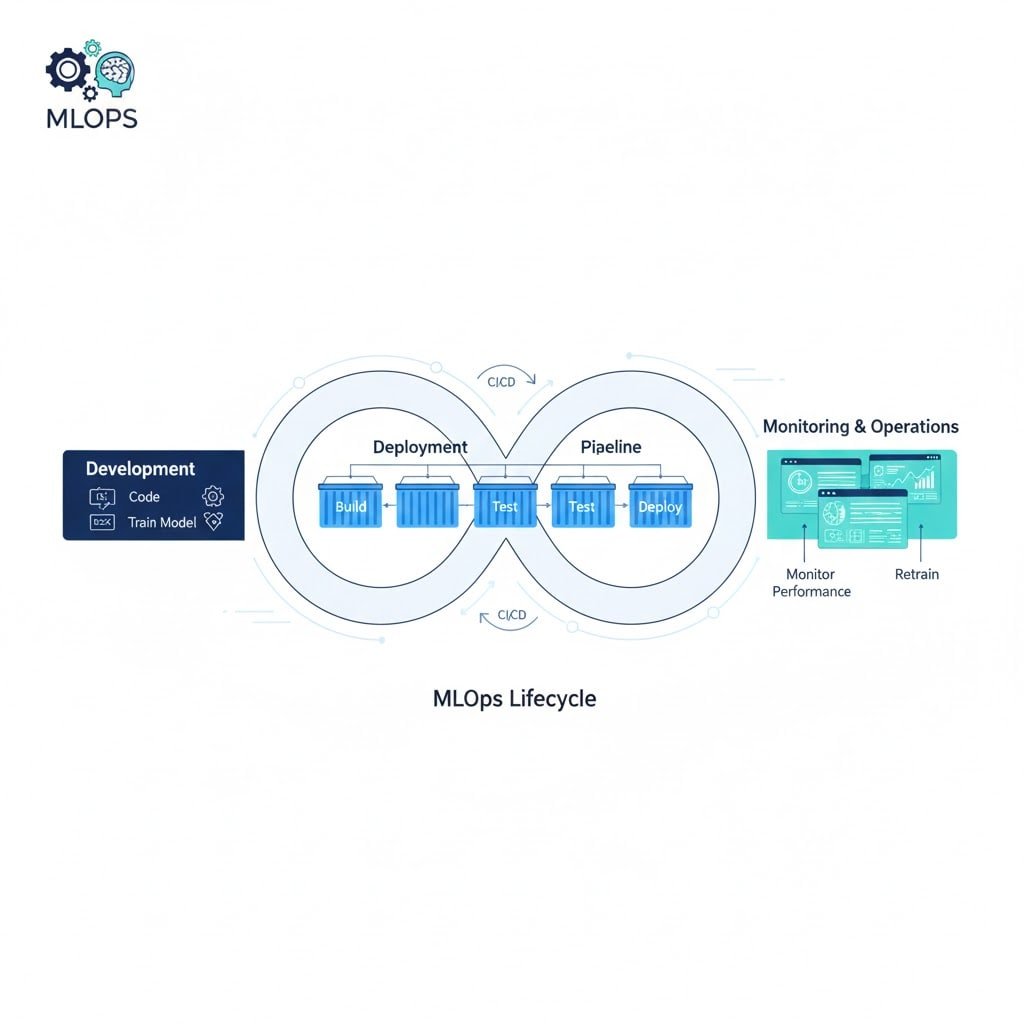
Hire MLOps Engineer: Enterprise-Grade AI Infrastructure & LLMOps
Scale your AI initiatives from experimental notebooks to robust global production systems. We provide the elite engineering talent needed to build, deploy, and govern intelligent pipelines.
At Viston, we understand that a model is only as good as the infrastructure that supports it. With over 15+ years of technical expertise and a portfolio of 2,860+ satisfied clients across the USA, Europe, and Australia, we bridge the gap between data science and reliable operations. Whether you need “LLMOps in a Box” for rapid deployment or complex Edge AI intelligence, our pre-vetted MLOps engineers ensure your AI delivers predictable value, not just experimental promise.
In the era of Agentic AI and Large Language Models, the bottleneck is no longer creating the model—it is operationalizing it. Organizations often face a “deployment gap” where high-value algorithms fail to reach production due to fragile infrastructure, lack of versioning, or compliance risks.
When you [Hire MLOps Engineer] talent from Viston, you are securing the backbone of your AI strategy. Our engineers specialize in automated retraining pipelines, continuous integration for ML (CML), and rigorous model governance. We move you beyond manual, siloed operations into a state of Enterprise Velocity. From enabling Generative AI for creative acceleration to deploying predictive intelligence on Edge IoT devices, Viston engineers build the systems that make AI responsible, scalable, and profitable. We serve major hubs including New York, London, Berlin, and Sydney, ensuring your infrastructure meets regional data sovereignty requirements.
End-to-End LLMOps Platform
Seamless orchestration of RAG agents and vector databases.
Automated Governance
Built-in drift detection and bias monitoring for responsible AI.
Edge & IoT Intelligence
Optimized model quantization for low-latency deployment.
Scalable Infrastructure
Kubernetes-native architectures that grow with your data needs.
Background: A Tier-1 New York bank struggled with “model drift” in their credit card fraud detection system. Tech Stack: Python, AWS SageMaker, MLflow, Kafka. Challenge: As spending patterns changed, the static model’s accuracy plummeted, leading to false positives and customer churn. Solution: Viston MLOps engineers implemented an automated drift detection pipeline that triggered retraining whenever statistical properties of live data diverged from training data. Results: Fraud detection accuracy improved by 18%, and false positives dropped by 30%. Testimonial:“Viston didn’t just patch our code; they built a self-healing system that adapts to market changes instantly.” – VP of Engineering
Predictive Maintenance for Manufacturing (Germany)
Background: A Berlin-based automotive supplier needed to deploy AI models onto factory floor robotic arms. Tech Stack: Azure IoT Edge, Docker, ONNX Runtime. Challenge: Cloud latency was too high for real-time safety stops; models needed to run locally on constrained hardware. Solution: We deployed an Edge AI architecture, quantizing models for 4x faster inference on local devices while maintaining a sync to the cloud for version control. Results: Reduced equipment downtime by 40% through real-time predictive alerts. Testimonial:“The latency reduction was a game-changer. Our compliance with German industrial safety standards is now fully automated.” – Head of Operations
Healthcare RAG Agent (UK)
Background: A London health-tech firm wanted a Generative AI chat interface for patient records but faced strict privacy hurdles. Tech Stack: LangChain, Pinecone, Kubernetes, Private LLaMA instances. Challenge: Public LLMs were non-compliant with NHS data standards; they needed a secure, private “LLMOps in a Box” solution. Solution: Our engineers built a private RAG (Retrieval-Augmented Generation) pipeline with strict role-based access control and local model hosting. Results: Fully GDPR-compliant deployment enabling doctors to query records in natural language, saving 15 hours/week per practitioner. Testimonial:“Viston operationalized a complex LLM strategy in weeks, ensuring we stayed on the right side of compliance.” – Chief Medical Officer
Technology Stack: Our MLOps
Core Languages & Frameworks
PyTorch
Go
Scikit-learn
Python
TensorFlow
LLMOps & GenAI
OpenAI API
Anthropic
LangChain
LLaMA Index
Hugging Face
Orchestration & Pipelines
Kubeflow
Airflow
MLflow
TFX
Containerization & Cloud
Kubernetes
Docker
AWS SageMaker
Azure ML
Google Vertex AI
Monitoring & Observability
Prometheus
Grafana
Arize AI
WhyLabs
Infrastructure as Code
Terraform
Ansible
Helm
CloudFormation
Feature
Starter
$22/hour
Recommended
Dedicated Developer
$2800/month
Dedicated Team
Custon Quote
Best For
Maintenance, ad-hoc bug fixes, staff augmentation during peak periods
Complex multi-phase projects, ongoing product development
Billing Cycle
Weekly or bi-weekly
Monthly
Monthly
Contract Terms
No minimum commitment
3-month minimum recommended
6-month minimum recommended
Get 15 Days Risk-Free Trial
Our 4-Step Hiring Process
Share Your Requirements
Tell us about your tech stack, the models you are running (LLM, Computer Vision, Tabular), and your compliance needs.
Pick the Best Talent
We match you with senior engineers from our pre-vetted pool who have specific domain experience in your industry.
Interview the Candidate
Conduct technical screenings or pair-programming sessions. Test their knowledge on chains, memory buffers, and vector embeddings to ensure a fit.
Onboard to Project
Your new MLOps engineer integrates into your Slack/Teams and Jira immediately, adopting your workflows and timezone.
Why Partner with Viston?
Global Talent Network
Access top-tier developers from major tech hubs in Europe, North America, and Australia.
Zero-Risk Trial
We offer a trial period to ensure the developer is the perfect fit for your stack.
IP Protection
All code and intellectual property created belongs 100% to your organization.
Continuous Upskilling
Our developers undergo weekly training on the latest LLM releases and security patches.
Enterprise Workflows
Intelligent RAG-Based Customer Support Agent
Automating Level 1 Support with Vector Search and LLMs
Connects incoming tickets to a vector database (Pinecone) via n8n to retrieve internal documentation context. The workflow passes this context to an LLM (OpenAI/Claude) to generate a technical response, drafts it in the helpdesk, and alerts a human for final approval.
Bi-Directional CRM & ERP Sync
Real-time Data Consistency for Sales and Inventory
Uses webhooks to listen for changes in Salesforce. The n8n workflow transforms the payload using custom JavaScript to match the ERP schema, handles complex nested JSON arrays, and updates the SAP/NetSuite database, ensuring inventory counts match sales commitments instantly.
Automated Regulatory Compliance Reporting
Aggregating Logs for GDPR/ISO Audits
Scheduled n8n cron jobs pull audit logs from 15+ distinct SaaS tools. The workflow parses, normalizes, and formats the data into a standardized PDF report, encrypts the file, and uploads it to a secure cold storage bucket while notifying the DPO (Data Privacy Officer).
IoT Anomaly Detection & Alerting
Edge AI Processing for Manufacturing Health
Ingests high-frequency MQTT streams from factory floor machinery. The n8n workflow utilizes a Python node to run a lightweight statistical deviation model. If a threshold is breached, it triggers an urgent PagerDuty alert and creates a maintenance work order in Jira.
Top Reasons to Hire MLOps Engineer Experts from Viston
Enterprise-Grade Automation Architecture with Proven Frameworks
Accelerated Time-to-Market Stop letting models rot in notebooks. Our engineers build the CI/CD pipelines that reduce deployment time from months to days.
Risk & Compliance Mitigation We implement “Responsible AI” by design. From bias detection to GDPR data lineage, we ensure your AI is legally safe for deployment in the EU and US.
Cost Optimization AI compute is expensive. We optimize GPU usage and implement auto-scaling (and scaling down) to ensure you only pay for the inference you need.
Global Talent, Local Alignment Whether you are in London, New York, or Berlin, our engineers work in your time zone, ensuring real-time collaboration and rapid incident response.
Future-Proof Architecture We don’t just script; we build platforms. Our architectures are designed to handle the LLMs of today and the autonomous agents of tomorrow.
What is the difference between a Data Scientist and an MLOps Engineer?
A Data Scientist builds the mathematical model (the “brain”). An MLOps Engineer builds the road, the traffic lights, and the delivery trucks (the “infrastructure”) that allow that model to serve customers reliably. You need Viston MLOps engineers to take the Data Scientist’s work out of the lab and into the real world.
Can you support "LLMOps" and Generative AI specifically?
Yes. This is a core competency. We help companies manage the specific challenges of Large Language Models, such as prompt management, context window optimization, vector database maintenance, and “hallucination” monitoring.
How do you handle data privacy for European clients (GDPR)?
We are deeply experienced with EU data sovereignty. We can deploy models on-premise or in region-specific cloud zones. We implement data anonymization pipelines and ensure that no customer data is sent to third-party model providers without strict legal wrappers.
Do your engineers work in US and Australian time zones?
Absolutely. We offer global coverage. When you [Hire MLOps Engineer] talent from Viston, we align their working hours with your core team to ensure overlapping collaboration time for stand-ups and debugging.
What happens if our AI model performance degrades (Drift)?
This is exactly why you hire us. We set up automated monitoring systems (like Arize or customized Grafana dashboards) that alert your team immediately when input data changes or model confidence drops, triggering automated retraining protocols.
Can you integrate with our existing AWS/Azure/GCP setup?
Yes, we work extensively with clients in Germany, France, and the UK. We design agentic architectures that respect GDPR data sovereignty requirements, often utilizing locally hosted LLMs or compliant enterprise APIs.
What is the typical cost of hiring a MetaGPT developer?
Costs vary based on seniority and engagement model. However, investing in MetaGPT expertise often yields a high ROI by automating the work of multiple junior roles. Contact us for a precise quote based on your project scope.
What is the cost difference between hiring a developer vs. using an Agency?
Hiring through Viston offers a hybrid advantage. You get the cost-efficiency of dedicated resources (avoiding the high overhead of full-service agencies) backed by the management and guarantees of an established firm (avoiding the risk of freelancers). You get enterprise-grade talent at competitive rates with transparent billing.
Do your developers support multi-lingual Llama implementations?
Yes. We work with clients across Europe (Germany, France, Spain) and have experience fine-tuning Llama on non-English datasets. We can enhance the model’s multilingual capabilities for cross-border support automation and document translation, ensuring high-quality outputs in your target markets.
What industries do you specialize in?
We can structure a dedicated team to provide 24/7 monitoring and incident response (NOC). This ensures that critical alerts are acknowledged and triaged immediately, regardless of the hour, protecting your uptime and customer experience around the clock.
Unlock Business Growth with Expert MLOps Solutions
Don’t let your AI strategy stall in development. Partner with Viston to build the robust, scalable, and compliant infrastructure your enterprise deserves. Join 2,860+ clients who have transformed their data into intelligent action.