Deep Domain Fine-Tuning Expertise
General models often fail in niche industries. Our developers excel at curating datasets and fine-tuning models (like Llama 3 or Mistral) to understand specific medical, legal, or engineering terminologies, ensuring high relevance.
Production-Grade Inference Optimization
Building a demo is easy; scaling is hard. We specialize in optimizing model latency and throughput using techniques like vLLM and quantization, ensuring your application remains responsive and cost-effective at scale.
Advanced Multi-Agent Orchestration
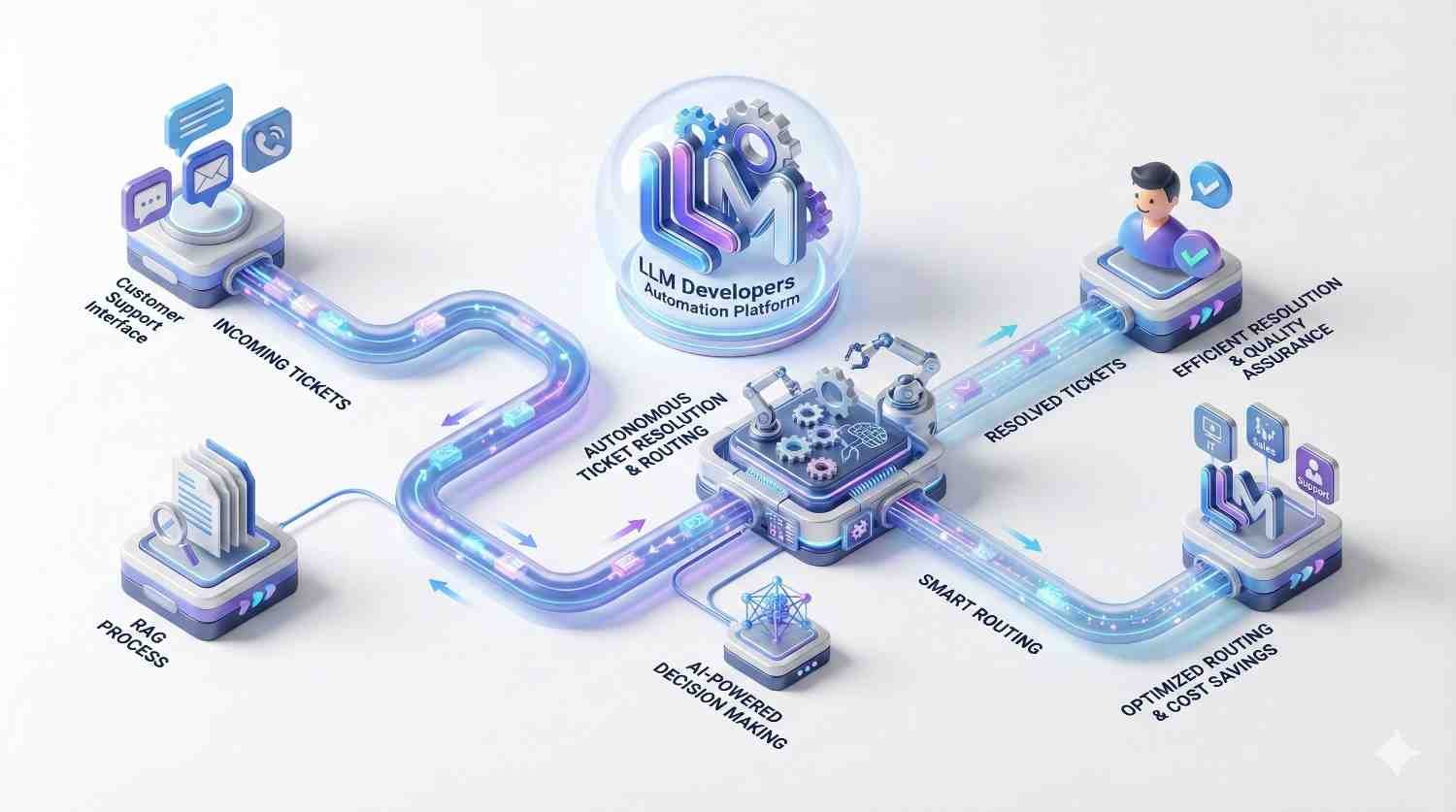
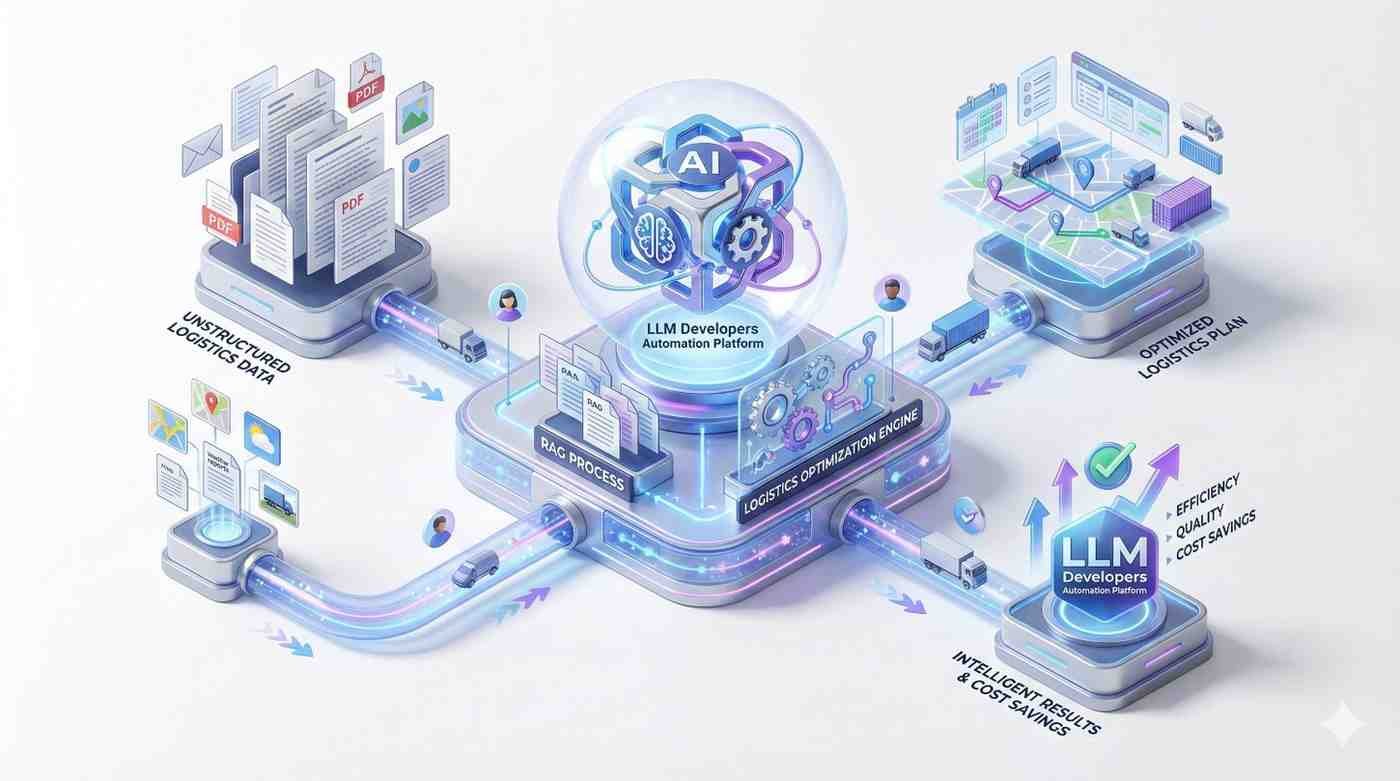
Move beyond simple chatbots. Our experts build complex agentic systems where multiple AI models collaborate to plan, execute, and verify tasks, automating entire business workflows rather than just generating text.
Strict Data Privacy & Governance
We understand that enterprise data is sacred. Our developers architect solutions that run within your VPC or on-premise, utilizing local LLMs to ensure sensitive data never leaves your controlled environment.
Seamless Legacy System Integration
AI shouldn’t stand alone. We connect LLMs to your existing ERPs, CRMs, and databases via robust APIs, allowing the AI to take action and read/write data directly within your current infrastructure.