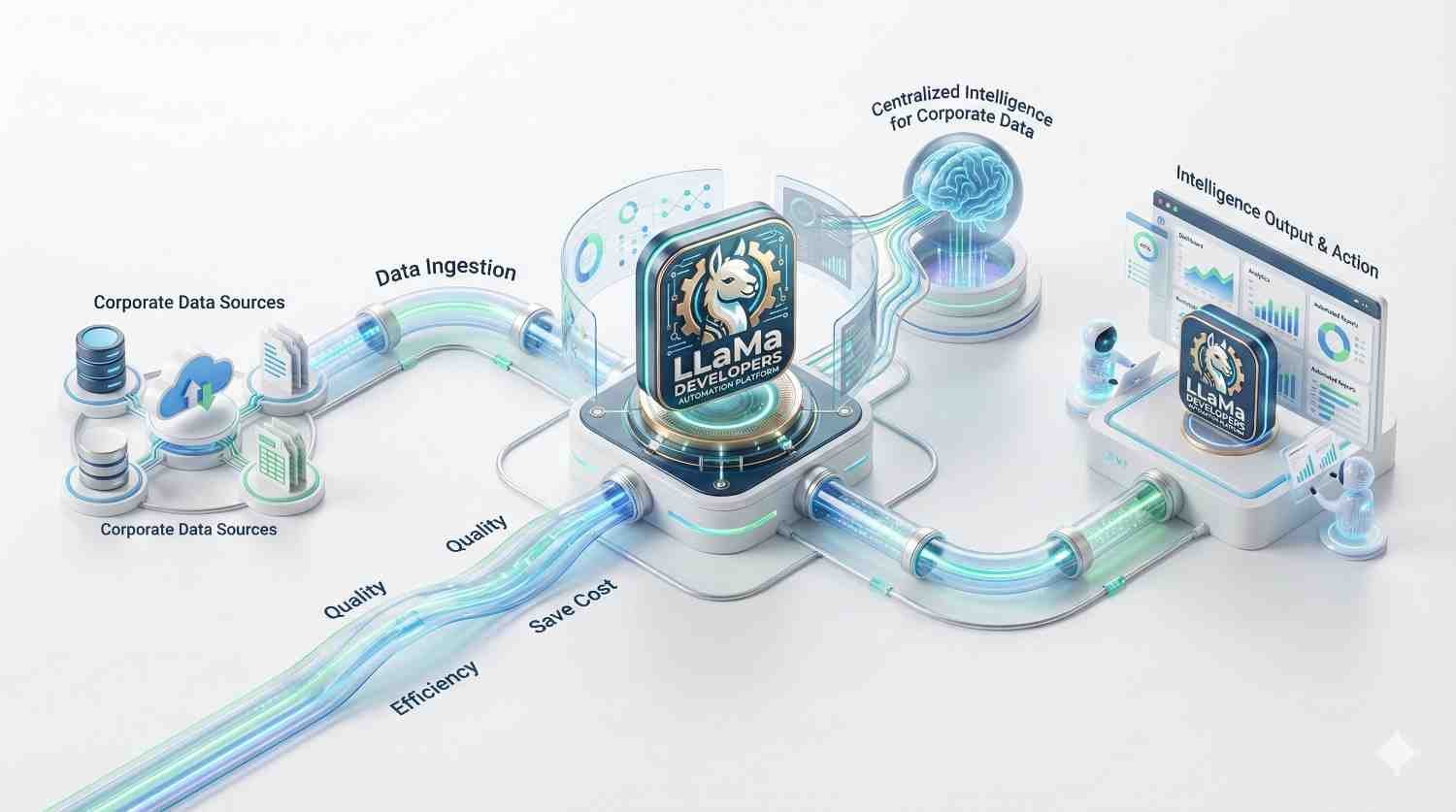
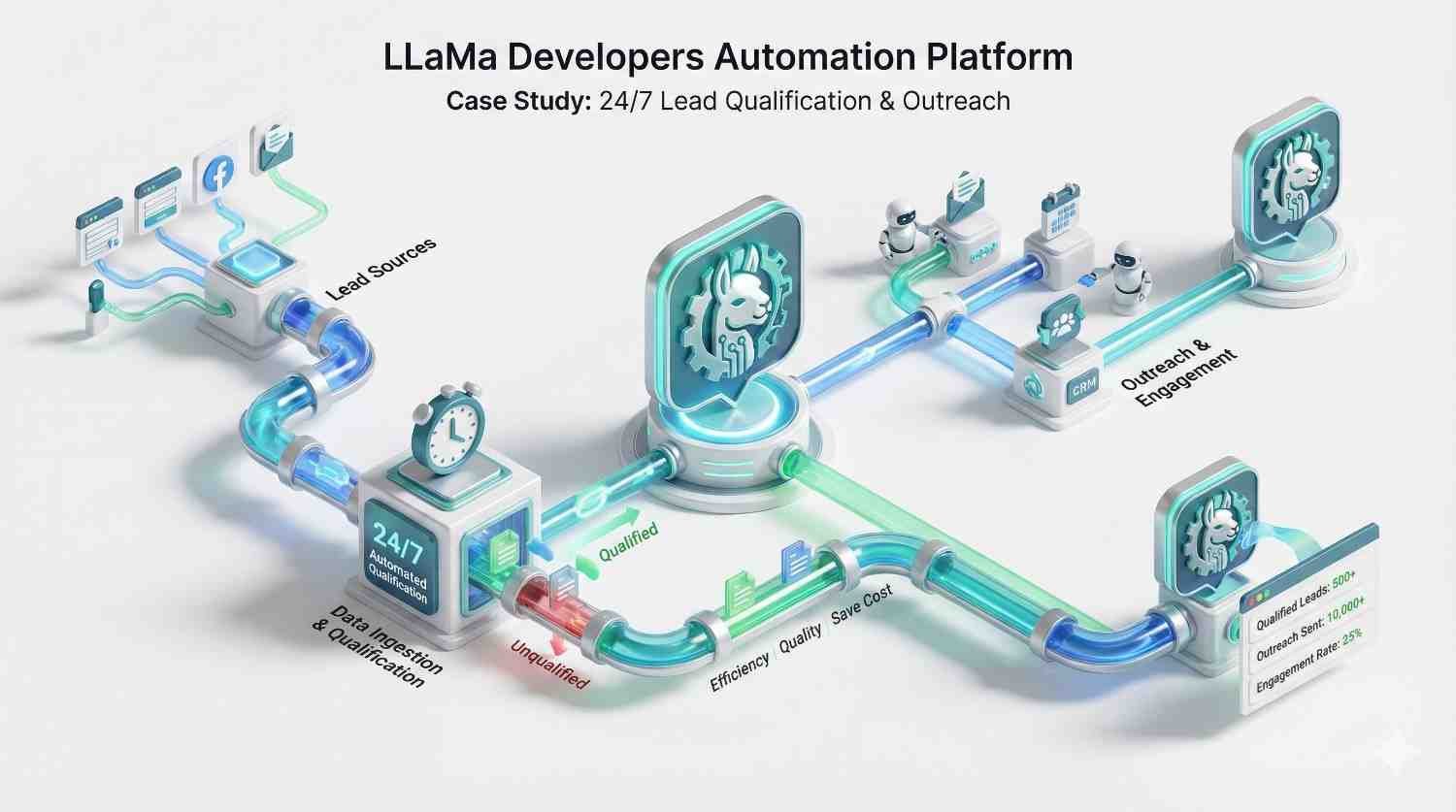
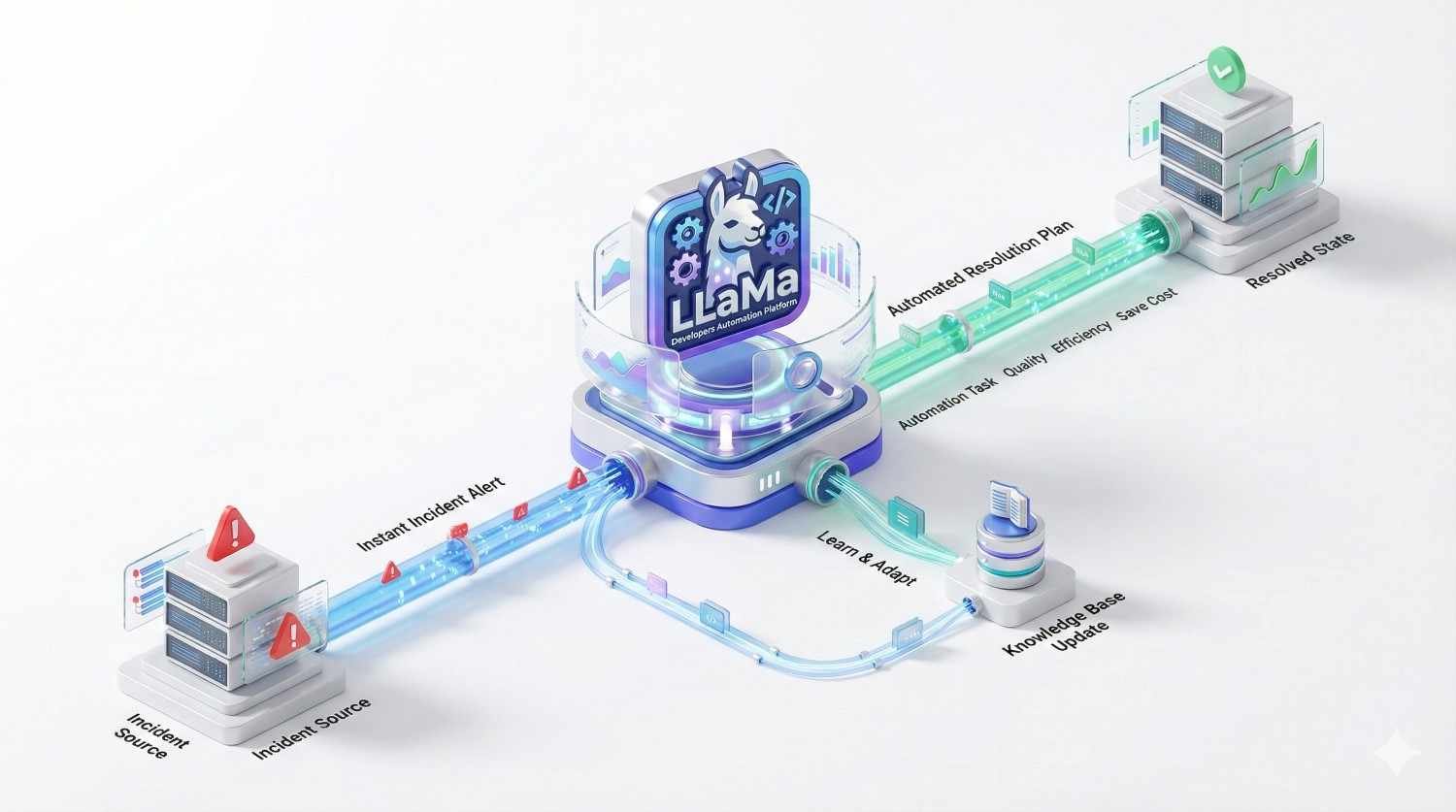
Absolutely. When you Hire LLaMa Developers from Viston, all code, model weights, adapters (LoRA), and datasets remain 100% your property. We operate on a “work for hire” basis. You retain full ownership of the AI asset, giving you the freedom to deploy, sell, or modify it without vendor lock-in.