MLOps & Model Monitoring: Keeping AI Agents Performing Optimally in Production
Here’s a startling statistic: around 75% of DIY AI and agent-based projects fail to make it into production. The reasons are many, from unforeseen complexities to a lack of proper oversight. But a primary culprit is the failure to anticipate what happens after an AI agent is deployed. This is where MLOps and robust model monitoring become not just best practices but essential components for success.
In 2025, the conversation around AI has shifted. It’s no longer just about building the most powerful models. It’s about ensuring those models perform reliably, predictably, and efficiently in the real world. For any organization, from enterprise C-suites to agile startups, understanding and implementing modern AI observability is the key to unlocking the true potential of your AI investments.
This post will guide you through the essentials of MLOps and model monitoring for AI agents. We’ll explore the challenges, the must-have monitoring stack, and the leading tools that can help you keep your AI agents performing at their peak. We’ll also provide an actionable playbook to get you started. Let’s dive in.

The High Stakes of AI in Production: Why MLOps Matters More Than Ever
Deploying an AI agent is just the beginning of its lifecycle. Without a solid MLOps framework, even the most promising models can falter in a live environment. The challenges are significant and multifaceted:
- The “It Worked in Dev” Problem: An AI agent that performs flawlessly in a controlled development environment can behave unpredictably when faced with real-world data. This gap between development and production is a primary reason for the high failure rate of AI projects.
- Lack of Visibility: When an AI agent produces an unexpected or incorrect output, pinpointing the cause can be like searching for a needle in a haystack without the right tools. This “black box” nature of some AI models makes debugging a nightmare.
- Silent Failures: Unlike traditional software that often fails with a clear error message, AI agents can fail silently. They might continue to produce outputs, but the quality degrades over time, leading to poor user experiences and potentially costly business mistakes.
- Scalability and Cost Management: As the usage of your AI agent grows, so do the computational costs. Without proper monitoring, these costs can spiral out of control, eroding the ROI of your AI initiative.
These challenges underscore the need for a modern approach to AI observability. Just as DevOps revolutionized software development, MLOps is doing the same for machine learning, providing the structure and tools necessary to manage the entire lifecycle of AI models.
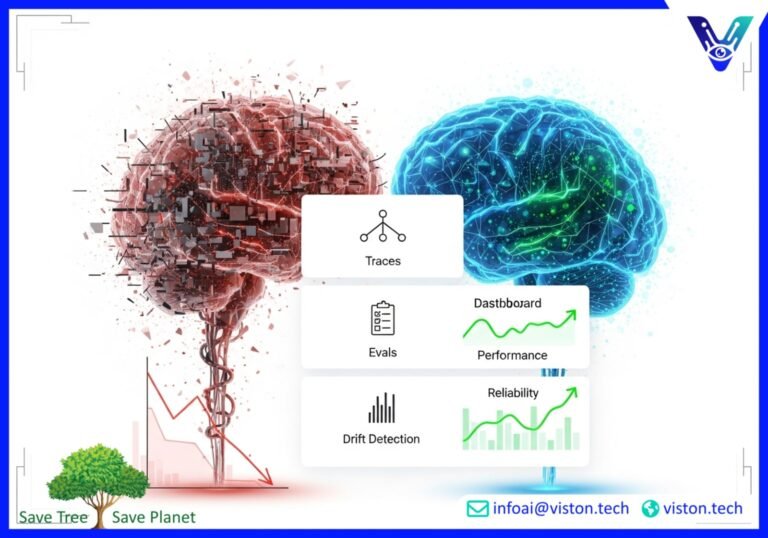
The Modern AI Observability Stack: Traces, Evals, and Drift
To effectively monitor AI agents, especially those built on large language models (LLMs), a modern observability stack should focus on three key pillars: tracing, evaluations (evals), and drift detection.
1. Tracing: Unpacking the “Why” Behind Your AI’s Actions
Tracing provides a detailed, step-by-step view of how your AI agent arrives at a decision. It’s like a flight recorder for your AI, capturing every internal process from the initial user prompt to the final output. This includes:
- LLM Calls: Every interaction with the underlying language model.
- Tool Usage: Any external tools or APIs the agent interacts with.
- Chains of Thought: The reasoning process of the agent.
By visualizing these traces, you can quickly diagnose issues, identify performance bottlenecks, and understand the intricate workings of your agent. This level of transparency is invaluable for debugging and optimization.
2. Evaluations (Evals): Continuously Measuring What Matters
Evaluations are about systematically assessing the quality of your AI agent’s outputs against predefined criteria. This goes beyond simple accuracy and delves into more nuanced aspects of performance. Key evaluation metrics include:
- Relevance: Does the output directly address the user’s query?
- Coherence: Is the output logical and easy to understand?
- Hallucination Rate: Is the agent inventing facts or providing misleading information?
- User Satisfaction: Are users finding the agent’s responses helpful? This can be measured through direct feedback mechanisms (e.g., thumbs up/down).
Regular evaluations, both automated and human-in-the-loop, are crucial for maintaining a high-quality user experience and ensuring your AI agent is meeting its objectives.
3. Drift Detection: Staying Ahead of a Changing World
The world is not static, and neither is the data your AI agent will encounter. Drift occurs when the statistical properties of the data in production change over time, diverging from the data the model was trained on. There are two main types of drift to monitor:
- Data Drift: This refers to changes in the input data. For example, a customer support bot might start receiving queries about a new product it wasn’t trained on.
- Concept Drift: This is a more subtle change where the meaning of the data itself evolves. A classic example is a spam filter that needs to adapt to new types of phishing attacks.
Detecting drift early is critical. It’s an early warning system that your model’s performance may be degrading and that it may need to be retrained or updated. For more in-depth information on drift, check out this comprehensive guide on monitoring LLMs for drift.
The Tools of the Trade: A Look at the 2025 MLOps Landscape
A host of powerful platforms have emerged to address the challenges of AI observability. Many of these tools integrate natively with popular AI development frameworks like LangChain and CrewAI, making it easier than ever to implement a robust monitoring strategy.
LangSmith
Developed by the creators of LangChain, LangSmith is a platform designed specifically for building and monitoring LLM-powered applications. Its key features include:
- Detailed Tracing: Provides full visibility into the execution of your LangChain agents.
- Playground for Prototyping: Allows for rapid experimentation and debugging.
- Hub for Prompts: A centralized place to manage and version your prompts.
LangSmith is an excellent choice for teams already invested in the LangChain ecosystem, offering a seamless integration experience.
Arize AI
Arize AI is a comprehensive AI observability platform that supports both traditional machine learning models and LLMs. Its strengths lie in:
- Drift Detection: Powerful tools for identifying data and concept drift.
- Performance Monitoring: Real-time dashboards to track key metrics.
- Explainability: Helps you understand the “why” behind your model’s predictions.
Arize is a great option for organizations that need a single platform to monitor a diverse range of AI models.
Langfuse
Langfuse is an open-source observability and analytics platform for LLM applications. It offers:
- Detailed Tracing: Similar to LangSmith, it provides deep insights into your application’s inner workings.
- Cost and Latency Tracking: Helps you keep an eye on the operational aspects of your AI agent.
- User Feedback Integration: Makes it easy to incorporate human feedback into your evaluation process.
For teams that prefer an open-source solution or want to self-host their observability platform, Langfuse is a compelling choice.
Weights & Biases (W&B)
Weights & Biases is a well-established MLOps platform that has expanded its capabilities to support LLMs. It excels at:
- Experiment Tracking: A central dashboard to log and compare all your model training experiments.
- Model Registry: A version control system for your machine learning models.
- Collaboration Tools: Features that facilitate teamwork among AI/ML engineers.
W&B is ideal for teams that need a robust platform to manage the entire MLOps lifecycle, from experimentation to production monitoring.
Key Metrics for AI Agent Performance
To effectively monitor your AI agents, it’s essential to track a combination of operational, quality, and business-level metrics. Here are some of the most important ones:
Operational Metrics
- Latency: How long does it take for the agent to respond to a user’s request?
- Cost per Interaction: How much does each interaction with the agent cost in terms of API calls and compute resources?
- Uptime: Is the agent consistently available and responsive?
Quality Metrics
- Task Completion Rate: What percentage of user requests does the agent successfully resolve without human intervention?
- Hallucination Rate: How often does the agent provide factually incorrect or nonsensical information?
- User Feedback Score: What is the average satisfaction rating from users?
Business Metrics
- Engagement Rate: How many users are actively interacting with the agent?
- Conversion Rate: If the agent is part of a sales or marketing funnel, how effectively is it driving conversions?
- Reduction in Support Tickets: For customer service agents, how much is it reducing the workload on human support staff?
For a deeper dive into the world of AI metrics, this article on AI and Machine Learning KPIs provides a wealth of information.
A Playbook for Implementing AI Model Monitoring
Getting started with MLOps and model monitoring doesn’t have to be an overwhelming process. Here’s a straightforward playbook to guide you:
- Define Your Goals and Metrics: Before you deploy your AI agent, clearly define what success looks like. What are the key performance indicators (KPIs) that matter most to your business?
- Choose the Right Tools: Based on your needs and existing technology stack, select the monitoring tools that are the best fit for your organization. Consider factors like ease of integration, scalability, and cost.
- Integrate Monitoring from Day One: Don’t treat monitoring as an afterthought. Integrate your chosen tools into your development process from the very beginning. This will make it much easier to transition from development to production.
- Establish Baselines: Once your agent is in a staging environment, run a series of tests to establish baseline performance metrics. This will give you a benchmark against which you can measure performance in production.
- Automate Alerts: Set up automated alerts to notify you when key metrics deviate from their baselines. This will allow you to be proactive in addressing potential issues before they impact your users.
- Create a Feedback Loop: Implement mechanisms for gathering user feedback and incorporate this data into your monitoring and evaluation process.
- Iterate and Improve: MLOps is not a one-time setup. It’s an ongoing process of monitoring, evaluating, and improving your AI agents based on real-world performance data.
The Future is Observable: Your Next Steps
The era of “build it and forget it” AI is over. As we move further into 2025, the ability to effectively monitor and maintain AI agents in production will be a key differentiator for successful organizations. By embracing MLOps and a modern observability stack, you can move beyond the ~75% failure rate and unlock the full potential of your AI investments.
Ready to ensure your AI agents are performing optimally? The journey starts with a commitment to observability and the right partners to guide you. At Viston AI, we specialize in building and maintaining high-performing, reliable AI-powered solutions. We can help you navigate the complexities of MLOps and model monitoring, ensuring your AI initiatives deliver real, measurable value.
Contact Viston AI today to learn how our AI-powered solutions can help you achieve your business goals.
Frequently Asked Questions (FAQs)
1. What is MLOps and why is it important for AI agents?
- MLOps, or Machine Learning Operations, is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. It’s crucial for AI agents because it provides the framework for monitoring, managing, and improving their performance over time, which helps to mitigate the high failure rate of AI projects.
2. What is the difference between data drift and concept drift?
- Data drift refers to changes in the input data your AI agent receives, while concept drift is a change in the relationship between the input data and the desired output. Both can degrade your model’s performance if not addressed.
3. How does observability for AI agents differ from traditional software monitoring?
- Traditional software monitoring focuses on metrics like uptime and error rates. AI observability goes deeper, incorporating tracing to understand the model’s decision-making process, evaluations to measure the quality of its outputs, and drift detection to monitor for changes in the data environment.
4. What are some of the key metrics I should be tracking for my AI agent?
- You should track a mix of operational metrics (latency, cost), quality metrics (task completion rate, hallucination rate), and business metrics (user engagement, conversion rate).
5. How do tools like LangSmith and Arize AI help with model monitoring?
- These tools provide the infrastructure for AI observability. They offer features like detailed tracing, performance dashboards, and automated drift detection, which make it much easier to monitor and manage your AI agents in production.
6. Can I implement MLOps for an existing AI agent?
- Yes, it’s possible to implement MLOps for an existing AI agent. However, it’s generally easier and more effective to incorporate monitoring and observability practices from the beginning of the development process.
7. What is the role of human feedback in AI model monitoring?
- Human feedback is a critical component of AI model monitoring. It provides a qualitative assessment of your agent’s performance that can be difficult to capture with automated metrics alone. This feedback is invaluable for fine-tuning your agent and improving the user experience.
8. How often should I retrain my AI agent?
- The frequency of retraining depends on several factors, including the rate of drift in your data and the specific requirements of your use case. Continuous monitoring will help you determine the optimal retraining schedule.
#MLOps #ModelMonitoring #AIObservability #LangSmith #DriftDetection #LLM #AIAgents #ArtificialIntelligence #MachineLearning #VistonAI
